Where Our Ground Truth Comes From
A look inside the lab studies behind North AI's model. Real people wearing EEG and eye-tracking watch real content, and the brain and eye signals we record there become the ground truth the model learns from, once, before it ever runs on your video.
The short version
Our model learns once, in a lab, from real people. They wear EEG caps to record brain activity and eye-tracking to record where they look, while they watch real content. Those recordings are the ground truth. We fit the model to them one time. After that, the model runs on your video using a normal webcam, with no headset and no lab required.
That is the honest shape of it. The neuroscience happens up front, with real brains and real eyes. What you use day to day is the model that learned from them.
We start in a lab, with real people
![]()
Before we predict how anyone will respond to your content, we watch how real people respond to content we already have.
In our lab, participants sit down and watch films, ads, and trailers while we record two things at once: their brain activity, through an EEG cap, and where their eyes go, through eye-tracking. The EEG tells us how the brain reacts moment to moment. The eye-tracking tells us what pulled their attention and what they skipped.
This is the ground truth. It is the actual signal from a real nervous system watching real content, rather than a synthetic stand-in or a survey filled in afterwards. When we say the model is grounded in neuroscience, this is what we mean.
Two honest notes. EEG only happens here, in the lab, with people who agreed to wear the cap. We never put EEG on your audience or on the people who test your content later. And the lab is where the brain data enters the model. It is not re-recorded every time you run a test.
Gazefilter: eye-tracking with just a webcam
The lab gives us our most detailed signal, but a headset does not scale. So the eye-tracking side had to work with hardware people already own. That is Gazefilter, our own eye-tracking, built to run on a plain front-facing camera.
Gazefilter reads the face with three models of increasing detail, from a light five-point model up to a sixty-eight-point one, and picks the one your camera and lighting can support. It follows head movement from the position of the nose and normalises it over the length of the content, so a two-minute clip and a thirty-second one are read on the same footing.
This is the bridge from the lab to everywhere else. The brain data stays in the lab. The eye signal, the part a webcam can capture, is what travels.
What a blink can tell us
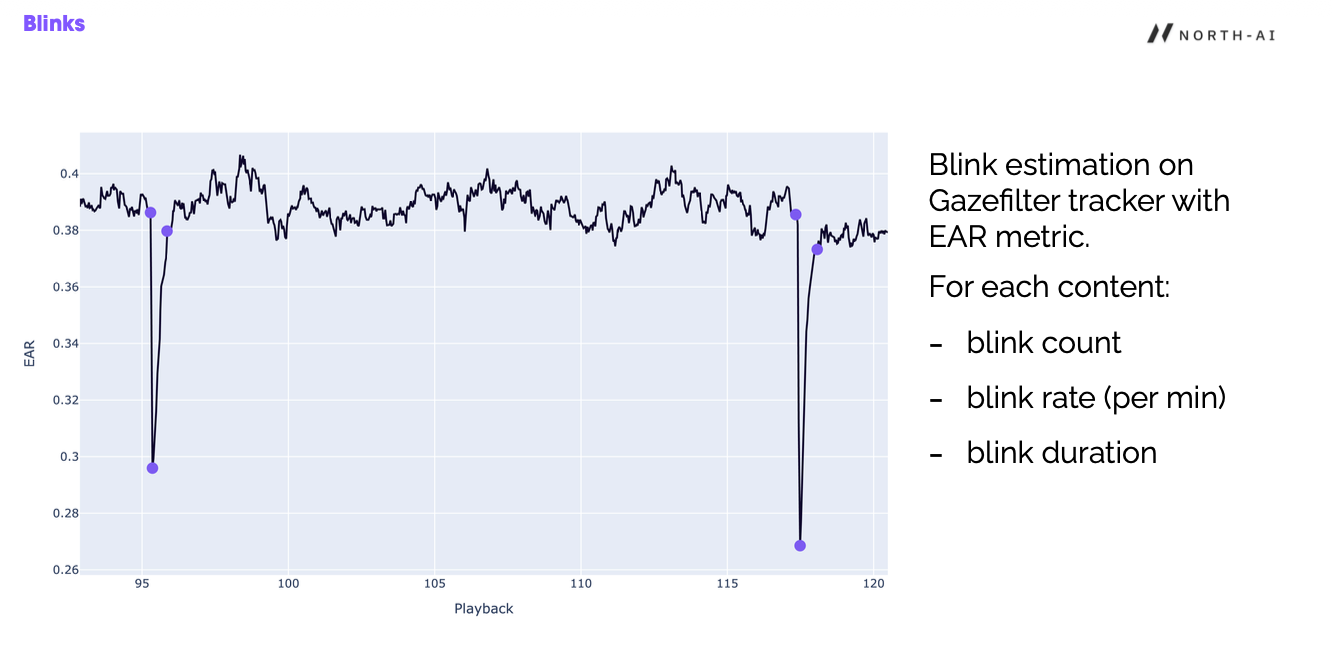
Each downward spike in the eye-aspect-ratio trace is a detected blink.
One of the simplest signals a camera can read is a blink. Gazefilter estimates blinks from the eye aspect ratio, or EAR, which drops sharply each time the eyes close. For every piece of content we get a blink count, a blink rate per minute, and how long each blink lasts.
Blinks matter because of a well-studied effect in neuroscience: people blink less when they are absorbed. The brain quietly holds a blink back so you do not miss the frame you care about. So a stretch of low blinking often lines up with a moment that held attention, and a burst of blinking often lines up with a lull.
This is a signal, not a verdict. A single blink says almost nothing. The pattern across a whole clip, and across many viewers, is what carries information.
Reading blinks across a room
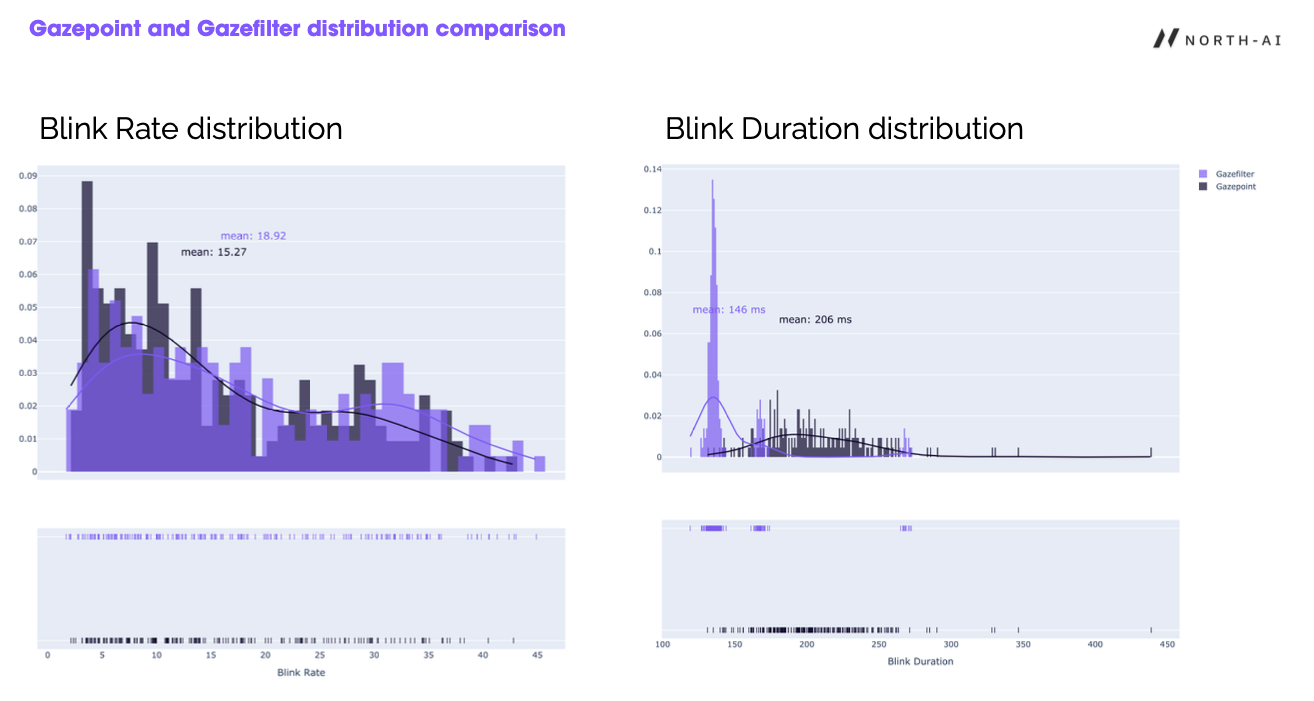
Blink rate and duration measured on a webcam sit in the same range as a research-grade tracker.
Two things make blinks more useful than they first look.
The first is calibration. We check Gazefilter's blink measurements against a dedicated research-grade eye-tracker to make sure the numbers hold up. The blink-rate and blink-duration distributions from both devices land in the same range, which is what gives us confidence the webcam is measuring the real thing.
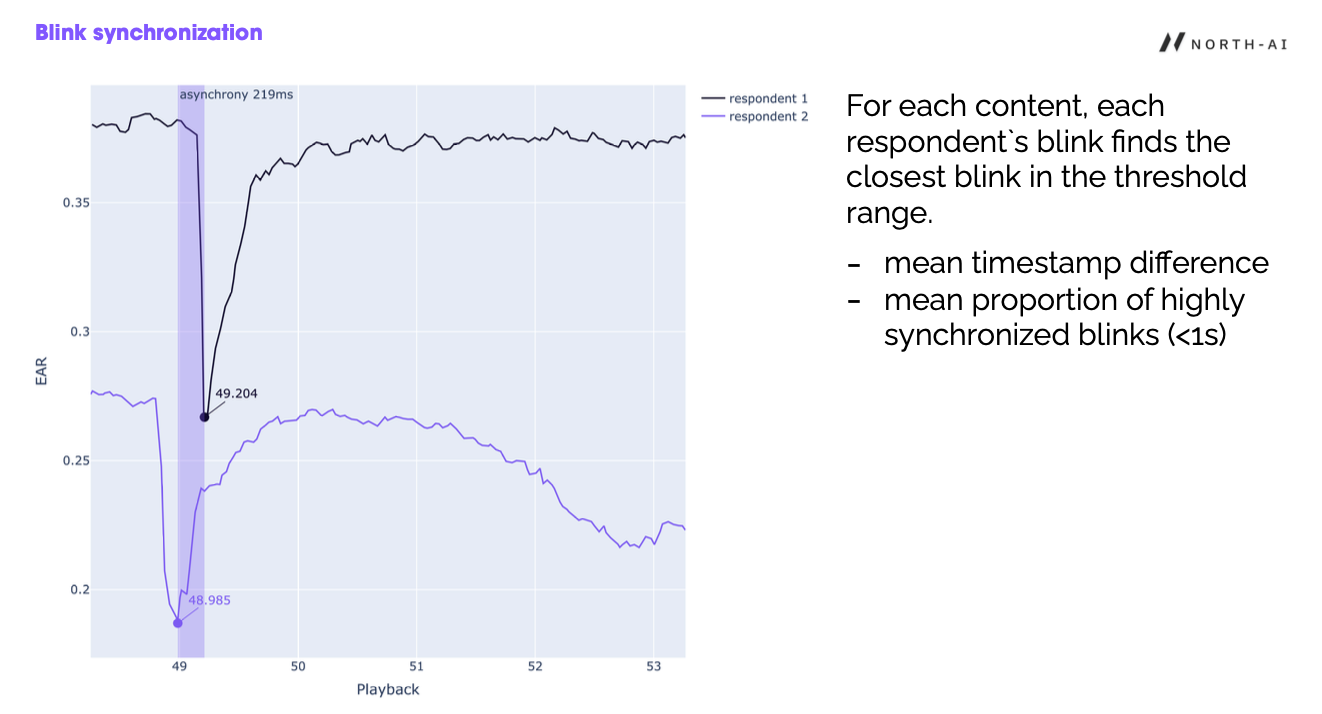
Two viewers reacting to the same moment, their blinks 219 milliseconds apart.
The second is synchrony. When several viewers blink at nearly the same instant, within a fraction of a second of each other, that shared pause usually marks a moment strong enough to move a room together. We measure the average gap between one viewer's blink and the next viewer's closest blink, and the share of blinks that land within a second of each other. Tight synchrony is a sign the content is steering attention rather than just filling time.
Does it line up with what people say?
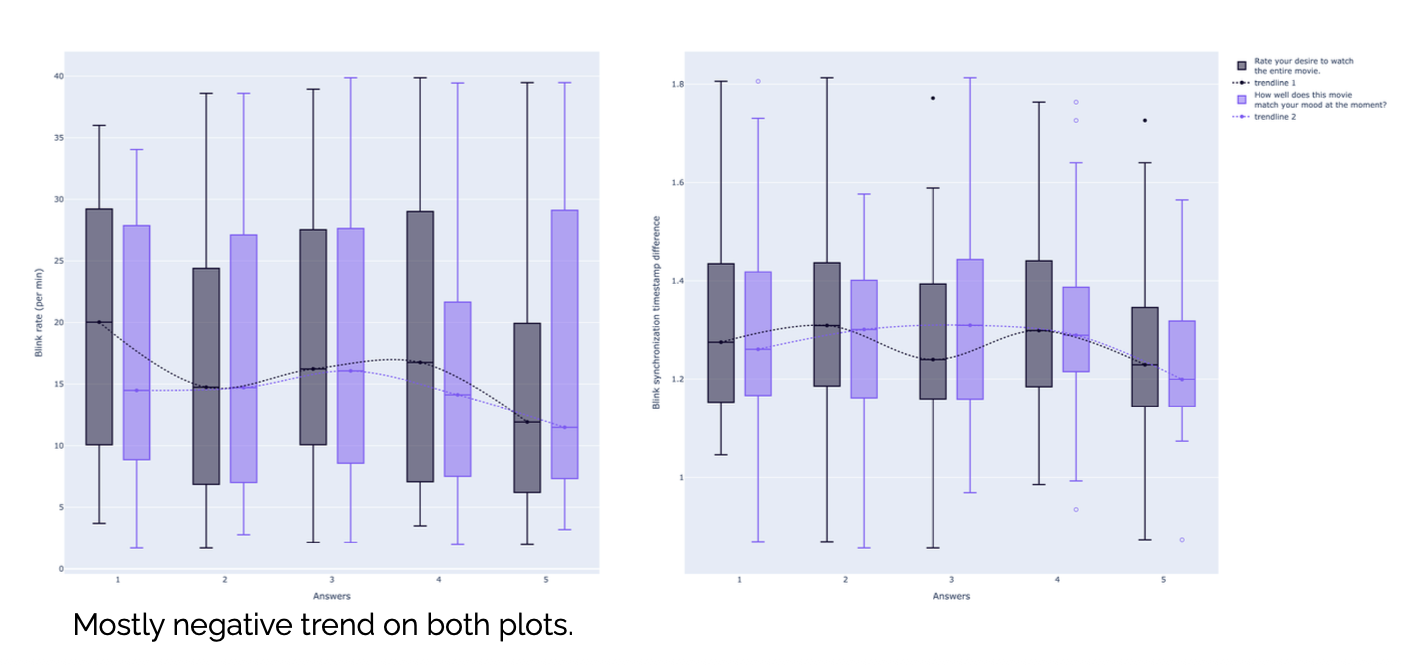
Blink rate plotted against what viewers reported feeling. Real, but modest.
Involuntary signals are only worth trusting if they agree with something we can check. So we compare blink behaviour against what viewers tell us in a short survey, on questions like how much they wanted to keep watching and how well the content matched their mood.
The relationships are real but modest, which is the honest result. Blink rate and blink synchrony shift with self-reported interest, though not cleanly enough to read one person's mood from a single number. That is why the model leans on many signals and many viewers rather than one tell. The self-report is a cross-check on the involuntary signal, not a replacement for it.
Self-report is one yardstick. An outside one is better still. In a study of 20 films, we compared how tightly viewers' gaze synchronised against each film's Metacritic score.
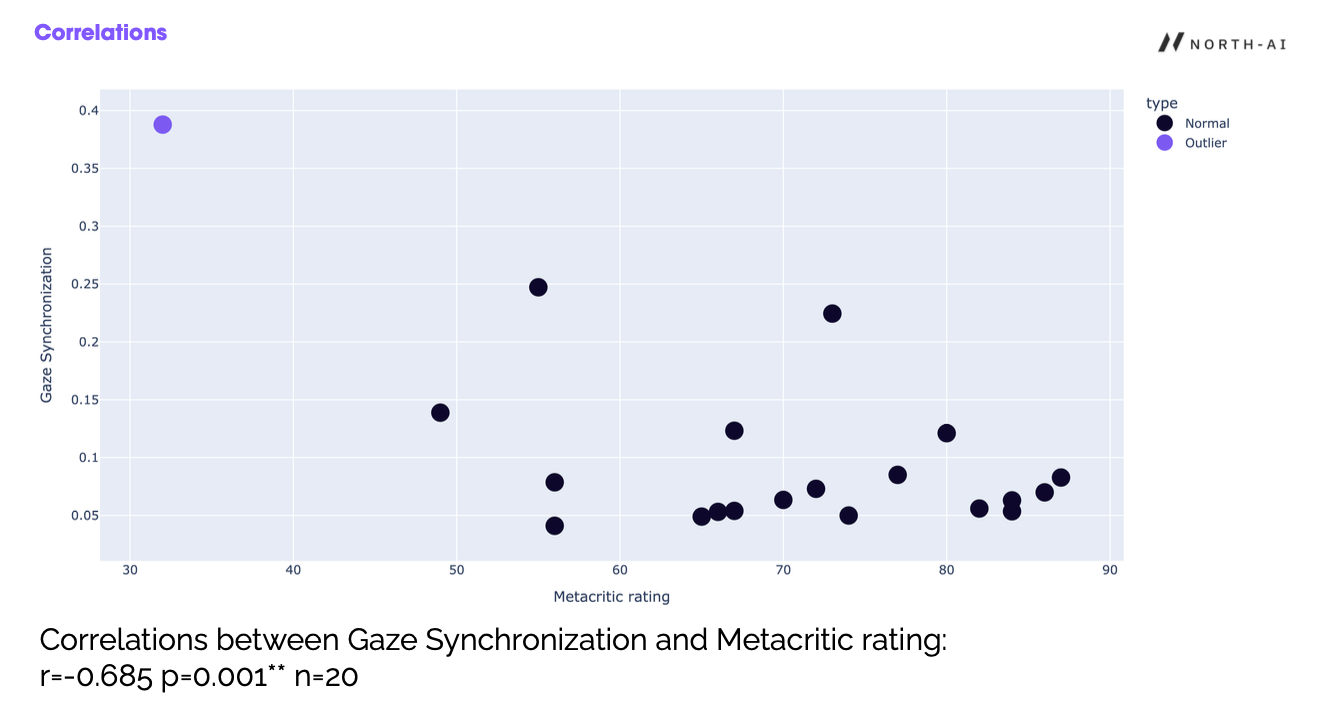
Gaze synchronisation against Metacritic score across 20 films. The one clear outlier is marked in purple.
The films that pulled viewers' gaze into the tightest sync were, on the whole, the better-reviewed ones (r = -0.685, p = 0.001). That is a strong relationship for a sample this small, and it is a correlation, not a promise. Twenty films with one obvious outlier is a reason to keep testing, not a law. But it points the same way as everything else here. When content genuinely holds a room, the eyes give it away.
From the lab to your content
When you upload a video, you are not starting a new lab study. You are running a model that already learned from one. The brain and eye recordings we gathered from real people are built into how it reads attention, second by second, so you get a response in minutes instead of weeks.
When the stakes are higher, a launch, a pitch, a decision you have to defend, you can go further and put the content in front of a real-viewer panel, tracked with the same webcam eye-tracking. That gives you fresh human data on your exact audience, and still no one wears a cap.
The short version, again: the neuroscience is real, it happens once, in a lab, with real brains and real eyes, and everything you touch afterwards is the model that learned from it.
Maintained by the North AI Research Team. Lab studies are conducted with consenting participants. EEG is used only in the lab, never on the audiences who test your content.
Frequently Asked Questions
What is the ground truth behind North AI's model?
It is data from real people in our lab. Participants watch real content while we record their brain activity with EEG and their eye movements with eye-tracking. The model is fitted to those recordings, so its predictions are anchored to how real nervous systems actually responded, not to a synthetic proxy.
Do you measure EEG on every viewer?
No. EEG is used only in the lab, to train and ground the model. When you test your own content, or when we run a real-viewer panel, we use eye-tracking through a normal webcam. No one wears an EEG cap at that stage.
What is Gazefilter?
Gazefilter is North AI's eye-tracking, built to run on an ordinary front-facing camera. It reads the face with three models of different detail, follows head movement from the position of the nose, and estimates blinks from the eye aspect ratio, so we can capture the eye signal without any specialist hardware.
What do blinks tell you about attention?
People tend to blink less when they are absorbed and more during lulls, an effect known as blink suppression. We track blink rate, blink duration, and how closely viewers blink in sync. On their own blinks are a weak signal, but across a whole clip and many viewers the pattern is informative.
Does the model retrain every time I run a test?
No. The model learns from the lab data once, offline. Running a test on your content is inference, applying what the model already knows. There is no live retraining and no real-time calibration loop.
Is a blink or a brain reading a definitive measure of quality?
No. Each signal is a marker, not a verdict. Blink patterns, gaze, and neural response all point in a direction, but the model combines many signals across many viewers rather than trusting any single reading, and high-stakes calls are confirmed with a real-viewer panel.
See how this works in practice
Book a private demo and we will run North AI live on your content.